
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- StringTokenizer
- K-MOOC
- Node
- html기초
- 우선순위큐
- K-MOOC 단국대학교 홍보단
- biginteger사용법
- TypeScript
- 티스토리챌린지
- 자바입력받기
- 딥러닝
- stringreader
- 블록체인
- national instruments
- 디스크블록할당
- 단국대학교 k-mooc
- 2차원배열정렬
- 자바문자열구분
- 머신러닝
- 컴파일시스템
- 블록체인강의
- Entity
- 블록체인 강의
- 자바스크립트
- 해시
- 자바
- CSS 기초
- 시스템프로그래밍
- 혁신의기술2:신뢰의미래 블록체인을 만나다
- 오블완
- Today
- Total
열정 실천
[AI] 003. 머신러닝 - 지도학습, 비지도학습, 강화학습 ++ 오버피팅 본문
머신러닝이란?
학습을 통해서 자동으로 성능을 개선할 수 있는 컴퓨터 알고리즘을 연구하는 것
학습 단계
데이터 수집 -> 데이터 전처리 - > 모델 정의 (가설 정의 -> 특징 정의 -> 목적 함수 정의)
예측 단계
데이터 -> 데이터 전처리 -> 특징 추출 -> 예측 -> 평가
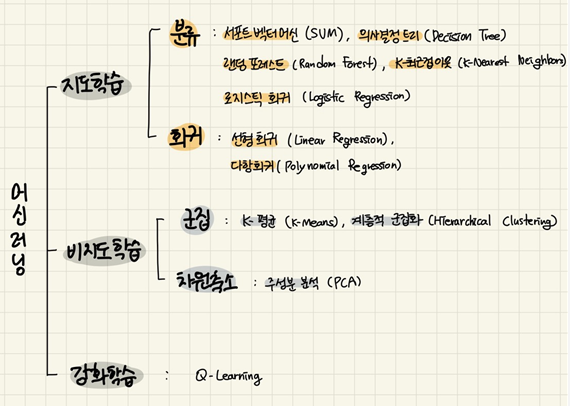
머신 러닝의 종류

지도 학습 (Supervised Learning)
기계에게 정답이 무엇인지를 알려주면서 학습
<종류>
분류 : 데이터가 속하는 범주 또는 클래스를 예측하는 문제
회귀 : 연속적인 수치 값을 예측하는 문제
비지도 학습 (Unsupervised Learning)
정답을 별도로 알려 주지 않고, 데이터 자체의 측성을 바탕으로 학습
<종류>
군집화 : 주어진 데이터 샘플들을 몇개의 클러스터로 그룹핑
차원축소 : 데이터의 특성을 유지하면서도 데이터를 표현하는 차원의 수를 줄임
준지도 학습 (Semi-supervised Learning)
정답이 있는 데이터와 정답이 없는 데이터를 모두 학습에 사용
강화 학습 (Reinforcement Learning)
기계(Agent)가 주어진 상태(State)에 대해 최적의 행동(Action)을 선택하는 학습
학습 데이터 대신 주어진 상태에 맞춘 행동의 결과에 대한 보상(Reward)를 주고, 이 보상을 이용하여 성능 향상
머신러닝 세부 종류
모델이 사용하는 데이터
🖍 학습 데이터
: 모델을 학습(파라미터 값 결정)하는 데 사용
*배치 학습 : 모든 학습 데이터를 한 꺼번에 학습 / Offline Learning / 시간&자원 많이 사용
*온라인 학습 : 데이터를 미니 배치 단위로 나누어 순차적으로 학습 / Online Learning / 메모리 절약
🖍 검증 데이터
: 학습이 완료된 모델을 검증하는 데 사용
- 오버피팅 방지 / 모델의 일반화 성능 향상 / 모델 선정
- 학습데이터와 중복되면 안됨
*K-fold 교차 검증 : 데이터 수가 적을 때 사용
🖍 테스트 데이터
: 최종 모델에 대한 바이어스 없는 평가에 사용
- 학습데이터와 중복되면 안됨
파라미터 & 하이퍼 파라미터
✨ 파라미터(Parameter)
인공지능 모델이 가진 학습가중치를 의미 --> 인위적으로 거의 변경하지 않음
✨ 하이퍼 파라미터(Hyper-Parameter)
인공지능 모델을 학습하기 위해 설정하는 인위적인 값들. configuration setting 값들을 의미
오버피팅과 언더피팅
오버피팅
모델이 학습 데이터에 지나치게 맞춰져, 새로운 데이터에 대해 일반화 능력이 떨어지는 현상이다. 학습 데이터의 노이즈나 불필요한 세부 사항까지 지나치게 학습한 결과로, 검증 데이터나 실제 데이터를 예측할 때 성능이 저하된다.
- 모델이 너무 복잡한 경우
모델의 파라미터 수가 데이터에 비해 과도하게 많아지면, 모델이 학습 데이터의 세부적인 특성까지 지나치게 학습하게 되어 오버피팅이 발생하기 쉽습니다. 특히 심층 신경망과 같은 복잡한 모델은 적은 데이터를 학습할 때 더욱 오버피팅되기 쉽습니다. - 학습 데이터가 부족한 경우
데이터가 충분하지 않으면, 모델이 학습 데이터에만 의존하여 일반화 능력이 떨어집니다. 이는 모델이 훈련 데이터의 패턴뿐만 아니라 노이즈나 특이값까지 학습하게 되어 오버피팅을 일으킵니다. - 데이터에 노이즈가 많은 경우
데이터에 불필요한 정보나 오류가 많을 때, 모델이 이러한 노이즈를 학습할 가능성이 큽니다. 노이즈는 실제 데이터의 일반적인 패턴과 다르기 때문에, 모델의 일반화 성능을 저하시킵니다. - 학습을 너무 오래 시킨 경우
학습이 지나치게 길어지면 모델이 훈련 데이터에 과도하게 맞춰져, 일반화에 불리한 방향으로 학습될 수 있습니다. 특히 에포크(epoch) 수가 많아지는 경우 검증 데이터에 대한 성능이 떨어질 수 있습니다. - 과적합 방지 기법 미사용
드롭아웃(Dropout), 정규화(Regularization), 조기 종료(Early Stopping) 등의 과적합 방지 기법을 사용하지 않으면 모델이 훈련 데이터에 과도하게 적합될 가능성이 높습니다. - 훈련 데이터와 테스트 데이터가 비슷하지 않은 경우
모델이 학습한 데이터와 테스트 데이터가 서로 다른 분포를 가지고 있으면 모델이 테스트 데이터에 일반화하기 어려워지며, 훈련 데이터에 과도하게 맞춘 모델이 테스트 데이터에서 낮은 성능을 보이게 됩니다.
오버피팅의 해결
- 데이터 증식
- 기존 데이터 변형
- 모델의 복잡도 감소 (모델의 파라미터 수 or 신경망의 hidden layer(은닉층) 수 감소)
- 드롭 아웃 (은닉층 내 일부 뉴런을 임시로 비활성화)
- 조기 종료
- 정규화
언더피팅
모델이 학습 데이터의 패턴을 충분히 학습하지 못해, 학습 데이터와 검증 데이터 모두에서 성능이 낮게 나오는 현상이다. 이는 주로 모델이 너무 단순하거나 데이터의 복잡성을 반영하지 못할 때 발생한다.

'CS > AI' 카테고리의 다른 글
| [AI] 006. 인공신경망 ANN (0) | 2024.11.24 |
|---|---|
| [AI] 005. 딥러닝 (6) | 2024.11.14 |
| [AI] 004. 머신러닝의 성능평가 (회귀-MAE,MSE,RMSE / 분류 - 심플 카운팅, ROC 곡선) (1) | 2024.11.12 |
| [AI] 002. 전문가 시스템 - 규칙기반 전문가 시스템, 퍼지규칙 (0) | 2024.11.10 |
| [AI] 001. 인공지능(AI)이란? - 인공지능의 역사와 미래 (9) | 2024.11.09 |



